Contents
- 15.1 Introduction
- 15.2 specification
-
15.3 selection and descriptors
- 15.3.1 @font-face
- 15.3.2 Selecting a Font: family, style, variant, weight, stretch and size
- 15.3.3 Font Data Qualification: unicode-range
- 15.3.4 Numeric Values: units-per-em
- 15.3.5 Referencing: src
- 15.3.6 Matching: panose-1, stemv, stemh, slope, cap-height, x-height, ascent, and descent
- 15.3.7 Synthesis: widths, bbox and definition-src
- 15.3.8 Alignment: baseline, centerline, mathline, and topline
- 15.3.9 Examples
- 15.4.1 Introducing Font Characteristics
- 15.4.2 Full name
- 15.4.3 Coordinate units on the em square
- 15.4.4 Central Baseline
- 15.4.5 Encoding
- 15.4.6 family name
- 15.4.7 Glyph widths
- 15.4.8 Horizontal stem width
- 15.4.9 Height of uppercase glyphs
- 15.4.10 Height of lowercase glyphs
- 15.4.11 Lower Baseline
- 15.4.12 Mathematical Baseline
- 15.4.13 Maximal bounding box
- 15.4.14 Maximum unaccented height
- 15.4.15 Maximum unaccented depth
- 15.4.16 Panose-1 number
- 15.4.17 Range of ISO 10646 characters
- 15.4.18 Top Baseline
- 15.4.19 Vertical stem width
- 15.4.20 Vertical stroke angle
- 15.5 matching algorithm
- 15.5.1 Mapping font weight values to font names
- 15.5.2 Examples of font matching
15.3 Font selection
The selection based on author's font properties, available fonts, etc.
See font matching algorithm- name matching
font that has the same family name as the requested font. (the appearance and the metrics might not necessarily match).
- intelligent matching
closest match in appearance to the requested font:
kind of font (text or symbol), nature of serifs, weight, cap height, x height, ascent, descent, slant, etc.
- synthesis
create a font that is a close in appearance and metrics.
The synthesizing information includes the matching information and requires accurate values for the parameters including width metrics, character to glyph substitution and position information. - download retrieve a font from another site.
Progressive rendering provides a temporary font (using name matching, intelligent matching, or synthesis) to allow content to be read while the requested font downloads. Then it replaces the temporary font. Requires metric information about the font to avoid re-layout.
15.3.1 Font Descriptions and @font-face
The font description provides the bridge between an author's specification and the data needed to format text and to render the abstract glyphs to the characters map the actual scalable outlines or bitmaps. Fonts are referenced by style sheet properties.
Font descriptors classifications :
- provide the match between the CSS usage of the font and the font description (these have the same names as the corresponding CSS font properties),
- URI for the location of the font data,
- further characterize the font, to provide a link between the font description and the font data.
Descriptions are specified via
@font-face { descriptor: value; descriptor: value; [… descriptor: value ]}Each rule specifies a value for descriptors, They apply within the context of the
@font-facerule in which they are defined.example:
A user agent examines@font-facerules for a font description defining "Comic Sans Ms". This example contains a rule that matche which has a URI where the font can be retrieved. If no matching@font-faceis found, the user agent attempts the same match as a user agent implementing CSS1.If the font had been installed it would have been matched.
15.3.2 Descriptors for Selecting a Font:
(Most are the same as "properties")
font-style : all | [ normal | italic | oblique ] [, [normal | italic | oblique] ]* ;Media:visual
font-variant : [normal | small-caps] [,[normal | small-caps]]* ; Media:visual
Cyrillic pryamoĭ faces may be labeled with a font-variant of small-caps, which will give better consistency with Latin faces
(and the companion kursiv face labeled with font-style italic).
font-weight : all | [ normal | bold | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900]
[, [normal | bold | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900] ]* ;Media: visual
exceptions from properties:- relative keywords (bolder, lighter) are not permitted.
- a comma-separated list of values is permitted
- 'all' is permitted, which means that the font will match for all possible weights;
font-stretch : all | [ normal | ultra-condensed | extra-condensed | condensed | semi-condensed | semi-expanded | expanded | extra-expanded | ultra-expanded ]
[, [ normal | ultra-condensed | extra-condensed | condensed | semi-condensed | semi-expanded | expanded | extra-expanded | ultra-expanded] ]* ; Media: visual-
exceptions from properties:
- relative keywords (wider, narrower) are not permitted
- a comma-separated list is permitted
- 'all' is permitted
font-size : all | <length> [, <length>]* ; Media: visual
Only absolute length units are permitted.
A comma-separated list of absolute lengths is permitted.The initial value of 'all' is suitable for most scalable fonts, so this descriptor is primarily for use in an @font-face for bitmap fonts, or scalable fonts designed to be rasterised at a restricted range of font sizes.
15.3.3 Descriptors for Font Data Qualification: unicode-range
The following descriptor is optional within a font definition, but is used to avoid checking or downloading a font that does not have sufficient glyphs to render a particular character.
- unicode-range (Descriptor)
-
Value: <urange> [, <urange>]* Initial: U+0-7FFFFFFF Media: visual
This is the descriptor for the range of ISO 10646 characters covered by the font.
The values of <urange> are expressed using hexadecimal numbers prefixed by "U+", corresponding to character code positions in ISO 10646 ([ISO10646]).
For example, U+05D1 is the ISO 10646 character 'Hebrew letter bet'. For values outside the Basic Multilingual Plane (BMP), additional leading digits corresponding to the plane number are added, also in hexadecimal, like this: U+A1234 which is the character on Plane 10 at hexadecimal code position 1234. At the time of writing no characters had been assigned outside the BMP. Leading zeros (for example, 0000004D) are valid, but not required.
The initial value of this descriptor covers not only the entire Basic Multilingual Plane (BMP), which would be expressed as U+0-FFFF, but also the whole repertoire of ISO 10646. Thus, the initial value says that the font may have glyphs for characters anywhere in ISO 10646. Specifying a value for unicode-range provides information to make searching efficient, by declaring a constrained range in which the font may have glyphs for characters. The font need not be searched for characters outside this range.
Values may be written with any number of digits. For single numbers, the character '?' is assumed to mean 'any value' which creates a range of character positions. Thus, using a single number:
- unicode-range: U+20A7
- no wild cards - it indicates a single character position (the Spanish peseta currency symbol)
- unicode-range: U+215?
- one wild card, covers the range 2150 to 215F (the fractions)
- unicode-range: U+00??
- two wild cards, covers the range 0000 to 00FF (Latin-1)
- unicode-range: U+E??
- two wild cards, covers 0E00 to 0EFF (the Lao script)
A pair of numbers in this format can be combined with the dash character to indicate larger ranges. For example:
- unicode-range: U+AC00-D7FF
- the range is AC00 to D7FF (the Hangul Syllables area)
Multiple, discontinuous ranges can be specified, separated by a comma. As with other comma-separated lists in CSS, any whitespace before or after the comma is ignored. For example:
- unicode-range: U+370-3FF, U+1F??
- This covers the range 0370 to 03FF (Modern Greek) plus 1F00 to 1FFF (Ancient polytonic Greek).
- unicode-range: U+3000-303F, U+3100-312F, U+32??, U+33??, U+4E00-9FFF, U+F9000-FAFF, U+FE30-FE4F
- Something of a worst case in terms of verbosity, this very precisely
indicates that this (extremely large) font contains only Chinese characters
from ISO 10646, without including any characters that are uniquely Japanese or
Korean. The range is 3000 to 303F (CJK symbols and punctuation) plus 3100 to
312F (Bopomofo) plus 3200 to 32FF (enclosed CJK letters and months) plus 3300
to 33FF (CJK compatibility zone) plus 4E00 to 9FFF (CJK unified Ideographs)
plus F900 to FAFF (CJK compatibility ideographs) plus FE30 to FE4F (CJK
compatibility forms).
A more likely representation for a typical Chinese font would be:
unicode-range: U+3000-33FF, U+4E00-9FFF
- unicode-range: U+11E00-121FF
- This font covers a proposed registration for Aztec pictograms, covering the range 1E00 to 21FF in plane 1.
- unicode-range: U+1A00-1A1F
- This font covers a proposed registration for Irish Ogham covering the range 1A00 to 1A1F
15.3.4 Descriptor for Numeric Values: units-per-em
The following descriptor specifies the number of "units" per em; these units may be used by several other descriptors to express various lengths, so units-per-em is required if other descriptors depend on it.
- units-per-em (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the number of the coordinate units on the em square, the size of the design grid on which glyphs are laid out.
15.3.5 Descriptor for Referencing: src
This descriptor is required for referencing actual font data, whether downloadable or locally installed.
- src (Descriptor)
-
Value: [ <uri> [format(<string> [, <string>]*)] | <font-face-name> ] [, <uri> [format(<string> [, <string>]*)] | <font-face-name> ]* Initial: undefined Media: visual
This is a prioritized, comma-separated list of external references and/or locally installed font face names. The external reference points to the font data on the Web. This is required if the WebFont is to be downloaded. The font resource may be a subset of the source font, for example it may contain only the glyphs needed for the current page or for a set of pages.
The external reference consists of a URI, followed by an optional hint regarding the format of font resource to be found at that URI, and this information should be used by clients to avoid following links to fonts in formats they are unable to use. As with any hypertext reference, there may be other formats available, but the client has a better idea of what is likely to be there, in a more robust way than trying to parse filename extensions in URIs.
The format hint contains a comma-separated list of format strings that denote well-known font formats. The user agent will recognize the name of font formats that it supports, and will avoid downloading fonts in formats that it does not recognize.
An initial list of format strings defined by this specification and representing formats likely to be used by implementations on various platforms is:
String Font Format Examples of common extensions "truedoc-pfr" TrueDoc Portable Font Resource .pfr "embedded-opentype" Embedded OpenType .eot "type-1" PostScript Type 1 .pfb, .pfa "truetype" TrueType .ttf "opentype" OpenType, including TrueType Open .ttf "truetype-gx" TrueType with GX extensions "speedo" Speedo "intellifont" Intellifont As with other URIs in CSS, the URI may be partial, in which case it is resolved relative to the location of the style sheet containing the @font-face.
The locally-installed <font-face-name> is the full font name of a locally installed font. The full font name is the name of the font as reported by the operating system and is the name most likely to be used in reader style sheets, browser default style sheets or possibly author style sheets on an intranet. Adornments such as bold, italic, and underline are often used to differentiate faces within a font family. For more information about full font names please consult the notes below.
The notation for a <font-face-name> is the full font name, which must be quoted since it may contain any character, including spaces and punctuation, and also must be enclosed in "local(" and ")".
Example(s):
- src: url("http://foo/bar")
- a full URI and no information about the font format(s) available there
- src: local("BT Century 751 No. 2 Semi Bold Italic")
- references a particular face of a locally installed font
- src: url("../fonts/bar") format("truedoc-pfr")
- a partial URI which has a font available in TrueDoc format
- src: url("http://cgi-bin/bar?stuff") format("opentype", "intellifont")
- a full URI, in this case to a script, which can generate two different formats - OpenType and Intellifont
- src: local("T-26 Typeka Mix"), url("http://site/magda-extra") format("type-1")
- two alternatives are given, firstly a locally installed font and secondly a downloadable font available in Type 1 format.
Access to locally installed fonts is via the <font-face-name>. The font face name is not truly unique, nor is it truly platform or font format independent, but at the moment it is the best way to identify locally installed font data. The use of the font face name can be made more accurate by providing an indication of the glyph complement required. This may be done by indicating the range of ISO 10646 character positions for which the font provides some glyphs (see unicode-range).
15.3.6 Descriptors for Matching: panose-1, stemv, stemh, slope, cap-height, x-height, ascent, and descent
These descriptors are optional for a CSS2 definition, but may be used if intelligent font matching or font size adjustment is desired by the author.
- panose-1 (Descriptor)
-
Value: [<integer>]{10} Initial: 0 0 0 0 0 0 0 0 0 0 Media: visual
This is the descriptor for the Panose-1 number and consists of ten decimal integers, separated by whitespace. A comma-separated list is not permitted for this descriptor, because the Panose-1 system can indicate that a range of values are matched. The initial value is zero, which means "any", for each PANOSE digit; all fonts will match the Panose number if this value is used. Use of the Panose-1 descriptor is strongly recommended for latin fonts. For further details, see Appendix C.
- stemv (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the vertical stem width of the font. If the value is undefined, the descriptor is not used for matching. If this descriptor is used, the units-per-em descriptor must also be used.
- stemh (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the horizontal stem width of the font. If the value is undefined, the descriptor is not used for matching. If this descriptor is used, the units-per-em descriptor must also be used.
- slope (Descriptor)
-
Value: <number> Initial: 0 Media: visual
This is the descriptor for the vertical stroke angle of the font.
- cap-height (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the number of the height of uppercase glyphs of the font. If the value is undefined, the descriptor is not used for matching. If this descriptor is used, the units-per-em descriptor must also be used.
- x-height (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the height of lowercase glyphs of the font. If the value is undefined, the descriptor is not used for matching. If this descriptor is used, the units-per-em descriptor must also be used. This descriptor can be very useful when using the font-size-adjust property, because computation of the z value of candidate fonts requires both the font size and the x-height; it is therefore recommended to include this descriptor.
- ascent (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the maximum unaccented height of the font. If the value is undefined, the descriptor is not used for matching. If this descriptor is used, the units-per-em descriptor must also be used.
- descent (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the Maximum unaccented depth of the font. If the value is undefined, the descriptor is not used for matching. If this descriptor is used, the units-per-em descriptor must also be used.
15.3.7 Descriptors for Synthesis: widths, bbox and definition-src
Synthesizing a font means, at minimum, matching the width metrics of the specified font. Therefore, for synthesis, this metric information must be available. Similarly, progressive rendering requires width metrics in order to avoid reflow of the content when the actual font has been loaded. Although the following descriptors are optional for a CSS2 definition, some are required if synthesizing (or reflow-free progressive rendering) is desired by the author. Should the actual font become available, the substitute should be replaced by the actual font. Any of these descriptors that are present will be used to provide a better or faster approximation of the intended font.
Of these descriptors, the most important are the widths descriptor and bbox which are used to prevent text reflow should the actual font become available. In addition, the descriptors in the set of descriptors used for matching can be used to provide a better synthesis of the actual font appearance.
This is the descriptor for the glyph widths. The value is a comma-separated list of <urange> values each followed by one or more glyph widths. If this descriptor is used, the units-per-em descriptor must also be used.
If the <urange> is omitted, a range of U+0-7FFFFFFF is assumed which covers all characters and their glyphs. If not enough glyph widths are given, the last in the list is replicated to cover that urange. If too many widths are provided, the extras are ignored.
Example(s):
For example:
widths: U+4E00-4E1F 1736 1874 1692 widths: U+1A?? 1490, U+215? 1473 1838 1927 1684 1356 1792 1815 1848 1870 1492 1715 1745 1584 1992 1978 1770In the first example a range of 32 characters is given, from 4E00 to 4E1F. The glyph corresponding to the first character (4E00) has a width of 1736, the second has a width of 1874 and the third, 1692. Because not enough widths have been provided, the last width replicates to cover the rest of the specified range. The second example sets a single width, 1490, for an entire range of 256 glyphs and then explicit widths for a range of 16 glyphs.
This descriptor cannot describe multiple glyphs corresponding to a single character, or ligatures of multiple characters. Thus, this descriptor can only be used for scripts that do not have contextual forms or mandatory ligatures. It is nevertheless useful in those situations. Scripts that require a one-to-many or many-to-many mapping of characters to glyphs cannot at present use this descriptor to enable font synthesis although they can still use font downloading or intelligent matching.
This is the descriptor for the maximal bounding box of the font. The value is a comma-separated list of exactly four numbers specifying, in order, the lower left x, lower left y, upper right x, and upper right y of the bounding box for the complete font.
- definition-src (Descriptor)
-
Value: <uri> Initial: undefined Media: visual
The font descriptors may either be within the font definition in the style sheet, or may be provided within a separate font definition resource identified by a URI. The latter approach can reduce network traffic when multiple style sheets reference the same fonts.
15.3.8 Descriptors for Alignment: baseline, centerline, mathline, and topline
These optional descriptors are used to align runs of different scripts with one another.
- baseline (Descriptor)
-
Value: <number> Initial: 0 Media: visual
This is the descriptor for the lower baseline of a font. If this descriptor is given a non-default (non-zero) value, the units-per-em descriptor must also be used.
- centerline (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the central baseline of a font. If the value is undefined, the UA may employ various heuristics such as the midpoint of the ascent and descent values. If this descriptor is used, the units-per-em descriptor must also be used.
- mathline (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the mathematical baseline of a font. If undefined, the UA may use the center baseline. If this descriptor is used, the units-per-em descriptor must also be used.
- topline (Descriptor)
-
Value: <number> Initial: undefined Media: visual
This is the descriptor for the top baseline of a font. If undefined, the UA may use an approximate value such as the ascent. If this descriptor is used, the units-per-em descriptor must also be used.
15.3.9 Examples
Example(s):
Given the following list of fonts:
Swiss 721 light light & light italic Swiss 721 roman, bold, italic, bold italic Swiss 721 medium medium & medium italic Swiss 721 heavy heavy & heavy italic Swiss 721 black black, black italic, & black #2 Swiss 721 Condensed roman, bold, italic, bold italic Swiss 721 Expanded roman, bold, italic, bold italic The following font descriptions could be used to make them available for download.
@font-face { font-family: "Swiss 721"; src: url("swiss721lt.pfr"); /* Swiss 721 light */ font-style: normal, italic; font-weight: 200; } @font-face { font-family: "Swiss 721"; src: url("swiss721.pfr"); /* The regular Swiss 721 */ } @font-face { font-family: "Swiss 721"; src: url("swiss721md.pfr"); /* Swiss 721 medium */ font-style: normal, italic; font-weight: 500; } @font-face { font-family: "Swiss 721"; src: url("swiss721hvy.pfr"); /* Swiss 721 heavy */ font-style: normal, italic; font-weight: 700; } @font-face { font-family: "Swiss 721"; src: url("swiss721blk.pfr"); /* Swiss 721 black */ font-style: normal, italic; font-weight: 800,900; /* note the interesting problem that the 900 weight italic doesn't exist */ } @font-face { font-family: "Swiss 721"; src: url(swiss721.pfr); /* The condensed Swiss 721 */ font-stretch: condensed; } @font-face { font-family: "Swiss 721"; src: url(swiss721.pfr); /* The expanded Swiss 721 */ font-stretch: expanded; }15.4 Font Characteristics
15.4.1 Introducing Font Characteristics
font characteristics found useful for client-side font matching, synthesis, and download for heterogeneous platforms accessing the Web. The data may be useful for any medium that needs to use fonts on the Web by some other means than physical embedding of the font data inside the medium.
These characteristics are used to characterize fonts. They are not specific to CSS, or to style sheets. In CSS, each characteristic is described by a font descriptor. These characteristics could also be mapped onto VRML nodes, or CGM Application Structures, or a Java API, or alternative style sheet languages. Fonts retrieved by one medium and stored in a proxy cache could be re-used by another medium, saving download time and network bandwidth, if a common system of font characteristics are used throughout.
A non-exhaustive list of examples of such media includes:
- 2-D vector formats
- Computer Graphics Metafile
- Simple Vector Format
- 3-D graphics formats
- VRML
- 3DMF
- Object embedding technologies
- Java
- Active-X
- Obliq
15.4.2 Full font name
This is the full name of a particular face of a font family. It typically includes a variety of non-standardized textual qualifiers or adornments appended to the font family name. It may also include a foundry name or abbreviation, often prepended to the font family name. It is only used to refer to locally installed fonts, because the format of the adorned name can vary from platform to platform. It must be quoted.
For example, the font family name of the TrueType font and the PostScript name may differ in the use of space characters, punctuation, and in the abbreviation of some words (e.g., to meet various system or printer interpreter constraints on length of names). For example, spaces are not allow in a PostScript name, but are common in full font names. The TrueType name table can also contain the PostScript name, which has no spaces.
The name of the font definition is important because it is the link to any locally installed fonts. It is important that the name be robust, both with respect to platform and application independence. For this reason, the name should be one that is not application- or language-specific.
The ideal solution would be to have a name that uniquely identifies each collection of font data. This name does not exist in current practice for font data. Fonts with the same face name can vary over a number of descriptors. Some of these descriptors, such as different complements of glyphs in the font, may be insignificant if the needed glyphs are in the font. Other descriptors, such as different width metrics, make fonts with the same name incompatible. It does not seem possible to define a rule that will always identify incompatibilities, but will not prevent the use of a perfectly suitable local copy of the font data with a given name. Therefore, only the range of ISO 10646 characters will be used to qualify matches for the font face name.
Since a prime goal of the font face name in the font definition is to allow a user agent to determine when there is a local copy of the specified font data, the font face name must be a name that will be in all legitimate copies of the font data. Otherwise, unnecessary Web traffic may be generated due to missed matches for the local copy.
15.4.3 Coordinate units on the em square
Certain values, such as width metrics, are expressed in units that are relative to an abstract square whose height is the intended distance between lines of type in the same type size. This square is called the em square and it is the design grid on which the glyph outlines are defined. The value of this descriptor specifies how many units the EM square is divided into. Common values are for example 250 (Intellifont), 1000 (Type 1) and 2048 (TrueType, TrueType GX and OpenType).
If this value is not specified, it becomes impossible to know what any font metrics mean. For example, one font has lowercase glyphs of height 450; another has smaller ones of height 890! The numbers are actually fractions; the first font has 450/1000 and the second has 890/2048 which is indeed smaller.
15.4.4 Central Baseline
This gives the position in the em square of the central baseline. The central baseline is used by ideographic scripts for alignment, just as the bottom baseline is used for Latin, Greek, and Cyrillic scripts.
15.4.5 Font Encoding
Either explicitly or implicitly, each font has a table associated with it, the font encoding table, that tells what character each glyph represents. This table is also referred to as an encoding vector.
In fact, many fonts contain several glyphs. Which of those glyphs should be used depends either on the rules of the language, or on the preference of the designer.
In Arabic, for example, all letters have four (or two) different shapes, depending on whether the letter is used at the start of a word, in the middle, at the end, or in isolation. It is the same character in all cases, and thus there is only one character in the source document, but when printed, it looks different each time.
There are also fonts that leave it to the graphic designer to choose from among various alternative shapes provided. Unfortunately, CSS2 doesn't yet provide the means to select those alternatives. Currently, it is always the default shape that is chosen from such fonts.
15.4.6 Font family name
This specifies the family name portion of the font face name. For example, the family name for Helvetica-Bold is Helvetica and the family name of ITC Stone Serif Semibold Italic is ITC Stone Serif. Some systems treat adornments relating to condensed or expanded faces as if they were part of the family name.
15.4.7 Glyph widths
This is a list of widths, on the design grid, for the glyph corresponding to each character. The list is ordered by ISO10646 code point. Widths cannot usefully be specified when more than one glyph maps to the same character or when there are mandatory ligatures.
15.4.8 Horizontal stem width
This value refers to the dominant stem of the font. There may be two or more designed widths. For example, the main vertical stems of Roman characters will differ from the thin stems on serifed "M" and "N", plus there may be different widths for uppercase and lowercase characters in the same font. Also, either by design or by error, all stems may have slightly different widths.
15.4.9 Height of uppercase glyphs
This measurement is the y-coordinate of the top of flat uppercase letters in Latin, Greek, and Cyrillic scripts, measured from the baseline. This descriptor is not necessarily useful for fonts that do not contain any glyphs from these scripts.
15.4.10 Height of lowercase glyphs
This measurement is the y-coordinate of the top of unaccented, non-ascending lowercase letters in Latin, Greek and Cyrillic scripts, measured from the baseline. Flat-topped letters are used, ignoring any optical correction zone. This is usually used as a ratio of lowercase to uppercase heights as a means to compare font families.

This descriptor is not useful for fonts that do not contain any glyphs from these scripts. Since the heights of lowercase and uppercase letters are often expressed as a ratio for comparing different fonts, it may be useful to set both the lowercase and uppercase heights to the same value for unicameral scripts such as Hebrew, where for mixed Latin and Hebrew text, the Hebrew characters are typically set at a height midway between the uppercase and lowercase heights of the Latin font.
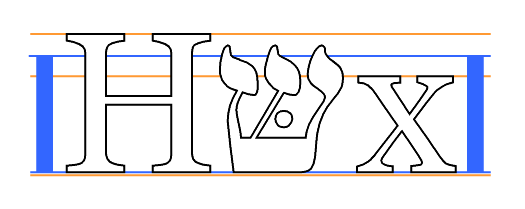
15.4.11 Lower Baseline
This gives the position in the em square of the lower baseline. The lower baseline is used by Latin, Greek, and Cyrillic scripts for alignment, just as the upper baseline is used for Sanscrit-derived scripts.
15.4.12 Mathematical Baseline
This gives the position in the em square of the mathematical baseline. The mathematical baseline is used by mathematical symbols for alignment, just as the lower baseline is used for Latin, Greek, and Cyrillic scripts.
15.4.13 Maximal bounding box
The maximal bounding box is the smallest rectangle enclosing the shape that results if all glyphs in the font are placed with their origins coincident, and then painted.
If a dynamically downloadable font has been generated by subsetting a parent font, the bbox should be that of the parent font.
15.4.14 Maximum unaccented height
This measurement, on the em square, is from the baseline to the highest point reached by any glyph, excluding any accents or diacritical marks.
15.4.15 Maximum unaccented depth
This measurement, on the em square, is from the baseline to the lowest point reached by any glyph, excluding any accents or diacritical marks.

15.4.16 Panose-1 number
Panose-1 is an industry standard TrueType font classification and matching technology. The PANOSE system consists of a set of ten numbers that categorize the key attributes of a Latin typeface, a classification procedure for creating those numbers, and Mapper software that determines the closest possible font match given a set of typefaces. The system could, with modification, also be used for Greek and Cyrillic, but is not suitable for unicameral and ideographic scripts (Hebrew, Armenian, Arabic, Chinese/Japanese/Korean).
15.4.17 Range of ISO 10646 characters
This indicates the glyph repertoire of the font, relative to ISO 10646 (Unicode). Since this is sparse (most fonts do not cover the whole of ISO 10646) this descriptor lists blocks or ranges that do have some coverage (no promise is made of complete coverage) and is used to eliminate unsuitable fonts (ones that will not have the required glyphs). It does not indicate that the font definitely has the required glyphs, only that it is worth downloading and looking at the font. See [ISO10646] for information about useful documents.
This method is extensible to future allocation of characters in Unicode, without change of syntax and without invalidating existing content.
Font formats that do not include this information, explicitly or indirectly, may still use this characteristic, but the value must be supplied by the document or style sheet author.
There are other classifications into scripts, such as the Monotype system (see [MONOTYPE]) and a proposed ISO script system. These are not readily extensible.
Because of this, classification of glyph repertoires by the range of ISO 10646 characters that may be represented with a particular font is used in this specification. This system is extensible to cover any future allocation.
15.4.18 Top Baseline
This gives the position in the em square of the top baseline. The top baseline is used by Sanscrit-derived scripts for alignment, just as the bottom baseline is used for Latin, Greek, and Cyrillic scripts.
15.4.19 Vertical stem width
This is the width of vertical (or near-vertical) stems of glyphs. This information is often tied to hinting, and may not be directly accessible in some font formats. The measurement should be for the dominant vertical stem in the font because there might be different groupings of vertical stems (e.g., one main one, and one lighter weight one as for an uppercase M or N).
15.4.20 Vertical stroke angle
This is the angle, in degrees counterclockwise from the vertical, of the dominant vertical strokes of the font. The value is negative for fonts that slope to the right, as almost all italic fonts do. This descriptor may also be specified for oblique fonts, slanted fonts, script fonts, and in general for any font whose vertical strokes are not precisely vertical. A non-zero value does not of itself indicate an italic font.
15.5 Font matching algorithm
This specification extends the algorithm given in the CSS1 specification. This algorithm reduces down to the algorithm in the CSS1 specification when the author and reader style sheets do not contain any @font-face rules.
Matching of descriptors to font faces must be done carefully. The descriptors are matched in a well-defined order to insure that the results of this matching process are as consistent as possible across UAs (assuming that the same library of font faces and font descriptions is presented to each of them). This algorithm may be optimized, provided that an implementation behaves as if the algorithm had been followed exactly.
- The user agent makes (or accesses) a database of relevant font-face
descriptors of all the fonts of which the UA is aware. If there are two fonts
with exactly the same descriptors, one of them is ignored. The UA may be aware of a font because:
- it has been installed locally
- it is declared using an @font-face rule in one of the style sheets linked to or contained in the current document
- it is used in the UA default style sheet, which conceptually exists in all UAs and is considered to have full @font-face rules for all fonts which the UA will use for default presentation, plus @font-face rules for the five special generic font families (see font-family) defined in CSS2
- At a given element and for each character in that element, the UA assembles the font properties applicable to that element. Using the complete set of properties, the UA uses the font-family descriptor to choose a tentative font family. Thus, matching on a family name will succeed before matching on some other descriptor. The remaining properties are tested against the family according to the matching criteria described with each descriptor. If there are matches for all the remaining properties, then that is the matching font face for the given element.
- If there is no matching font face within the font-family being processed by step 2, UAs that implement intelligent matching may proceed to examine other descriptors such as x-height, glyph widths, and panose-1 to identify a different tentative font family. If there are matches for all the remaining descriptors, then that is the matching font face for the given element. The font-family descriptor that is reflected into the CSS2 properties is the font family that was requested, not whatever name the intelligently matched font may have. UAs that do not implement intelligent matching are considered to fail at this step.
- If there is no matching font face within the font-family being processed by step 3, UAs that implement font downloading may proceed to examine the src descriptor of the tentative font face identified in step 2 or 3 to identify a network resource that is available, and of the correct format. If there are matches for all the remaining descriptors, then that is the matching font face for the given element and the UA may attempt to download this font resource. The UA may choose to block on this download or may choose to proceed to the next step while the font downloads. UAs that do not implement font download, or are not connected to a network, or where the user preferences have disabled font download, or where the requested resource is unavailable for whatever reason, or where the downloaded font cannot be used for whatever reason, are considered to fail at this step.
- If there is no matching font face within the font-family being processed by step 3, UAs that implement font synthesis may proceed to examine other descriptors such as x-height, glyph widths, and panose-1 to identify a different tentative font family for synthesis. If there are matches for all the remaining descriptors, then that is the matching font face for the given element and synthesis of the faux font may begin. UAs that do not implement font synthesis are considered to fail at this step.
- If all of steps 3, 4 and 5 fail, and if there is a next alternative font-family in the font set, then repeat from step 2 with the next alternative font-family.
- If there is a matching font face, but it doesn't contain glyph(s) for the current character(s), and if there is a next alternative font-family in the font sets, then repeat from step 2 with the next alternative font-family. The unicode-range descriptor may be used to rapidly eliminate from consideration those font faces that do not have the correct glyphs. If the unicode-range descriptor indicates that a font contains some glyphs in the correct range, it may be examined by the UA to see if it has that particular one.
- If there is no font within the family selected in 2, then use the inherited or UA-dependent font-family value and repeat from step 2, using the best match that can be obtained within this font. If a particular character cannot be displayed using this font, the UA should indicate that a character is not being displayed (for example, using the 'missing character' glyph).
- UAs that implement progressive rendering and have pending font downloads may, once download is successful, use the downloaded font as a font family. If the downloaded font is missing some glyphs that the temporary progressive font did contain, the downloaded font is not used for that character and the temporary font continues to be used.
Note. The above algorithm can be optimized to avoid having to revisit the CSS2 properties for each character.
The per-descriptor matching rules from (2) above are as follows:
- font-style is tried first. 'italic' will be satisfied if there is either a face in the UA's font database labeled with the CSS keyword 'italic' (preferred) or 'oblique'. Otherwise the values must be matched exactly or font-style will fail.
- font-variant is tried next. 'normal' matches a font not labeled as 'small-caps'; 'small-caps' matches (1) a font labeled as 'small-caps', (2) a font in which the small caps are synthesized, or (3) a font where all lowercase letters are replaced by uppercase letters. A small-caps font may be synthesized by electronically scaling uppercase letters from a normal font.
- font-weight is matched next, it will never fail. (See font-weight below.)
- font-size must be matched within a UA-dependent margin of tolerance. (Typically, sizes for scalable fonts are rounded to the nearest whole pixel, while the tolerance for bitmapped fonts could be as large as 20%.) Further computations, e.g., by 'em' values in other properties, are based on the font-size value that is used, not the one that is specified.
15.5.1 Mapping font weight values to font names
The font-weight property values are given on a numerical scale in which the value '400' (or 'normal') corresponds to the "normal" text face for that family. The weight name associated with that face will typically be Book, Regular, Roman, Normal or sometimes Medium.
The association of other weights within a family to the numerical weight values is intended only to preserve the ordering of weights within that family. User agents must map names to values in a way that preserves visual order; a face mapped to a value must not be lighter than faces mapped to lower values. There is no guarantee on how a user agent will map font faces within a family to weight values. However, the following heuristics tell how the assignment is done in typical cases:
- If the font family already uses a numerical scale with nine values (as e.g., OpenType does), the font weights should be mapped directly.
- If there is both a face labeled Medium and one labeled Book, Regular, Roman or Normal, then the Medium is normally assigned to the '500'.
- The font labeled "Bold" will often correspond to the weight value '700'.
- If there are fewer then 9 weights in the family, the default algorithm for filling the "holes" is as follows. If '500' is unassigned, it will be assigned the same font as '400'. If any of the values '600', '700', '800', or '900' remains unassigned, they are assigned to the same face as the next darker assigned keyword, if any, or the next lighter one otherwise. If any of '300', '200', or '100' remains unassigned, it is assigned to the next lighter assigned keyword, if any, or the next darker otherwise.
There is no guarantee that there will be a darker face for each of the font-weight values; for example, some fonts may have only a normal and a bold face, others may have eight different face weights.
The following two examples show typical mappings.
Assume four weights in the "Rattlesnake" family, from lightest to darkest: Regular, Medium, Bold, Heavy.
First example of font-weight mapping Available faces Assignments Filling the holes "Rattlesnake Regular" 400 100, 200, 300 "Rattlesnake Medium" 500 "Rattlesnake Bold" 700 600 "Rattlesnake Heavy" 800 900 Assume six weights in the "Ice Prawn" family: Book, Medium, Bold, Heavy, Black, ExtraBlack. Note that in this instance the user agent has decided not to assign a numeric value to "Example2 ExtraBlack".
Second example of font-weight mapping Available faces Assignments Filling the holes "Ice Prawn Book" 400 100, 200, 300 "Ice Prawn Medium" 500 "Ice Prawn Bold" 700 600 "Ice Prawn Heavy" 800 "Ice Prawn Black" 900 "Ice Prawn ExtraBlack" (none) 15.5.2 Examples of font matching
Example(s):
The following example defines a specific font face, Alabama Italic. A panose font description and source URI for retrieving a truetype server font are also provided. Font-weight and font-style descriptors are provided to describe the font. The declaration says that the weight will also match any request in the range 300 to 500. The font family is Alabama and the adorned font name is Alabama Italic.
@font-face { src: local("Alabama Italic"), url(http://www.fonts.org/A/alabama-italic) format("truetype"); panose-1: 2 4 5 2 5 4 5 9 3 3; font-family: Alabama, serif; font-weight: 300, 400, 500; font-style: italic, oblique; }Example(s):
The next example defines a family of fonts. A single URI is provided for retrieving the font data. This data file will contain multiple styles and weights of the named font. Once one of these @font-face definitions has been dereferenced, the data will be in the UA cache for other faces that use the same URI.
@font-face { src: local("Helvetica Medium"), url(http://www.fonts.org/sans/Helvetica_family) format("truedoc"); font-family: "Helvetica"; font-style: normal } @font-face { src: local("Helvetica Oblique"), url("http://www.fonts.org/sans/Helvetica_family") format("truedoc"); font-family: "Helvetica"; font-style: oblique; slope: -18 }Example(s):
The following example groups three physical fonts into one virtual font with extended coverage. In each case, the adorned font name is given in the src descriptor to allow locally installed versions to be preferentially used if available. A fourth rule points to a font with the same coverage, but contained in a single resource.
@font-face { font-family: Excelsior; src: local("Excelsior Roman"), url("http://site/er") format("intellifont"); unicode-range: U+??; /* Latin-1 */ } @font-face { font-family: Excelsior; src: local("Excelsior EastA Roman"), url("http://site/ear") format("intellifont"); unicode-range: U+100-220; /* Latin Extended A and B */ } @font-face { font-family: Excelsior; src: local("Excelsior Cyrillic Upright"), url("http://site/ecr") format("intellifont"); unicode-range: U+4??; /* Cyrillic */ } @font-face { font-family: Excelsior; src: url("http://site/excels") format("truedoc"); unicode-range: U+??,U+100-220,U+4??; }Example(s):
This next example might be found in a UA's default style sheet. It implements the CSS2 generic font family, serif by mapping it to a wide variety of serif fonts that might exist on various platforms. No metrics are given since these vary among the possible alternatives.
@font-face { src: local("Palatino"), local("Times New Roman"), local("New York"), local("Utopia"), url("http://somewhere/free/font"); font-family: serif; font-weight: 100, 200, 300, 400, 500; font-style: normal; font-variant: normal; font-size: all }